1The Hong Kong University of Science and Technology
2Deakin University
3VinAI Research
4Woven Planet North America, Level 5
European Conference on Computer Vision (ECCV), 2022 (Oral Presentation)
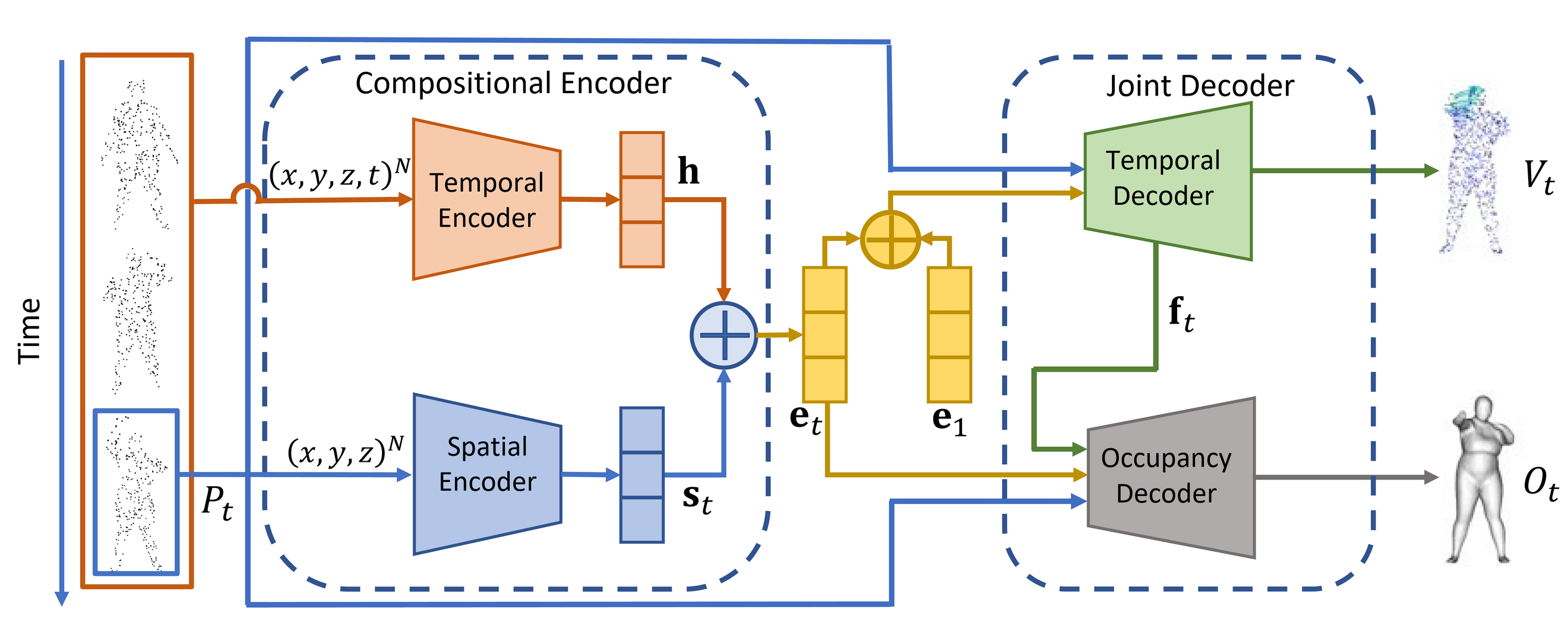
Overview of our Joint Learning for 4D Reconstruction and Flow Estimation.
Abstract
Object reconstruction from 3D point clouds has achieved impressive progress in the computer vision and computer
graphics research field. However, reconstruction from time-varying point clouds (a.k.a. 4D point clouds) is
generally overlooked. In this paper, we propose a new network architecture, namely RFNet-4D, that jointly
reconstructs objects and their motion flows from 4D point clouds. The key insight is that simultaneously
performing both tasks via learning spatial and temporal features from a sequence of point clouds can leverage
individual tasks and lead to improved overall performance. The proposed network can be trained using both
supervised and unsupervised learning. To prove this ability, we design a temporal vector field learning module
using an unsupervised learning approach for flow estimation, leveraged by supervised learning of spatial
structures for object reconstruction. Extensive experiments and analyses on benchmark dataset validated the
effectiveness and efficiency of our method. As shown in experimental results, our method achieves
state-of-the-art performance on both flow estimation and object reconstruction while performing much faster than
existing methods in both training and inference.
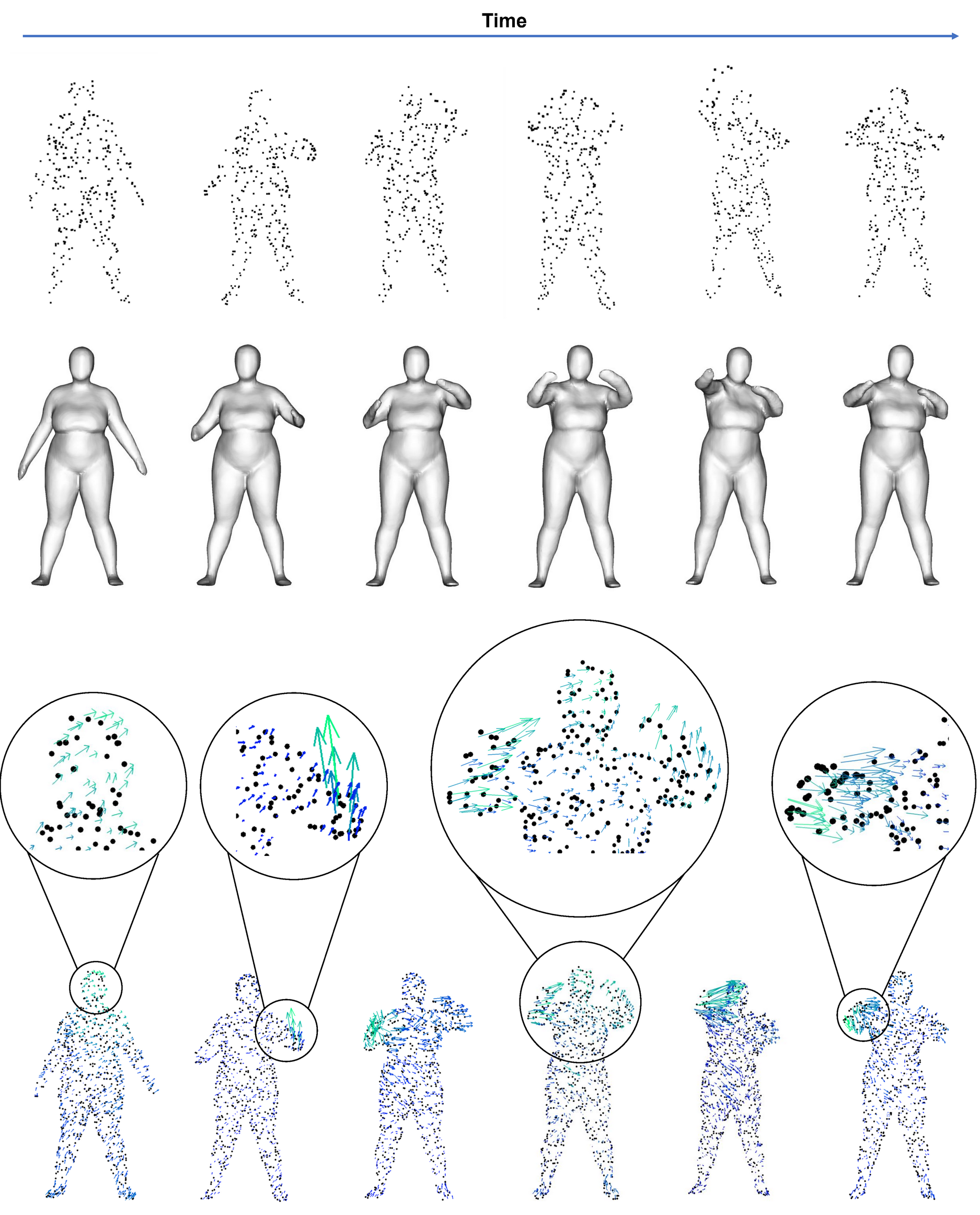
Given a sequence of time-varying 3D point clouds (first row), we jointly reconstruct corresponding 3D
geometric shapes (second row) and estimate their motion fields for every point cloud (third row).
Our Network Architecture
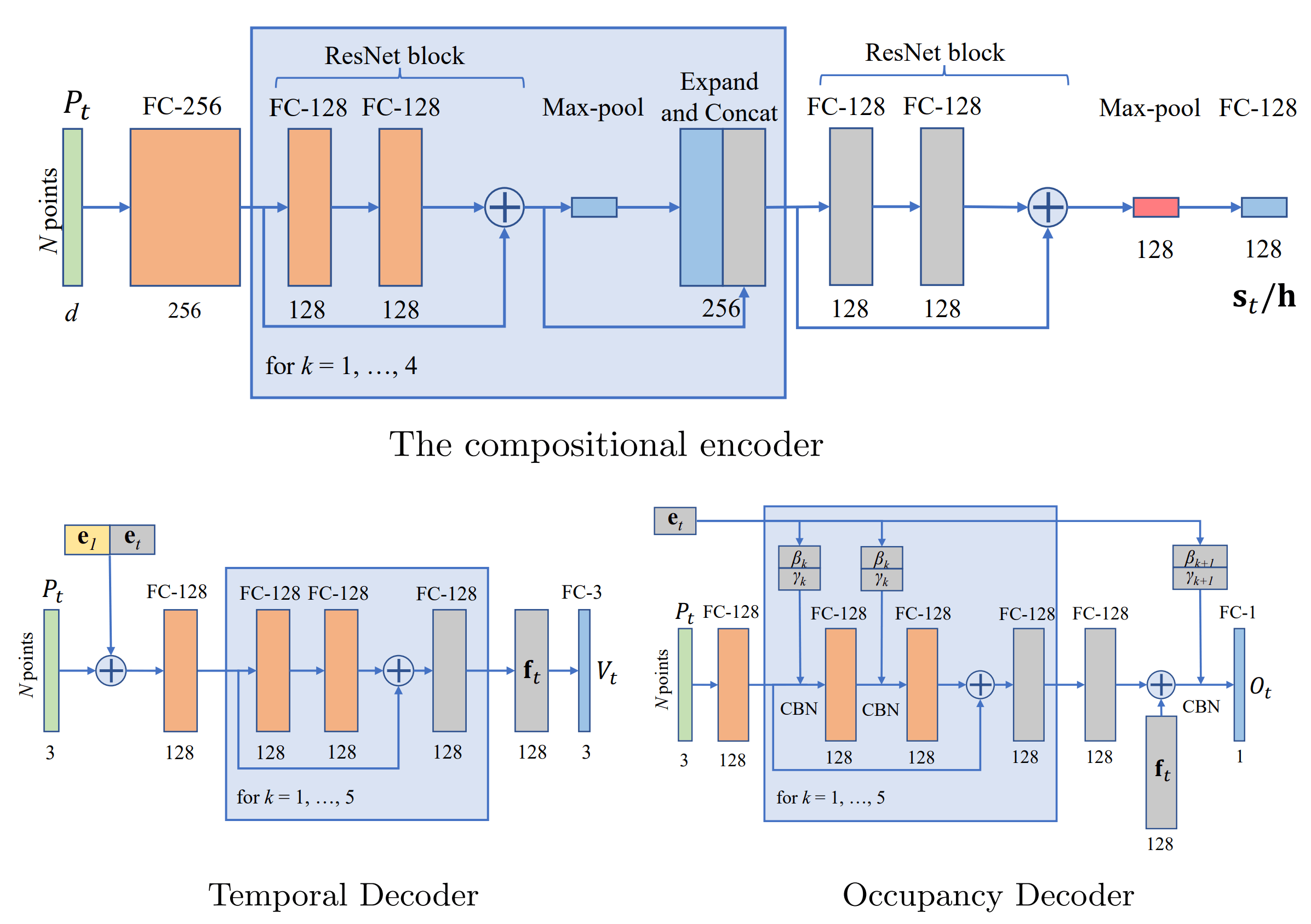
Network architecture of our Compositional encoder, temporal decoder and occupancy decoder.
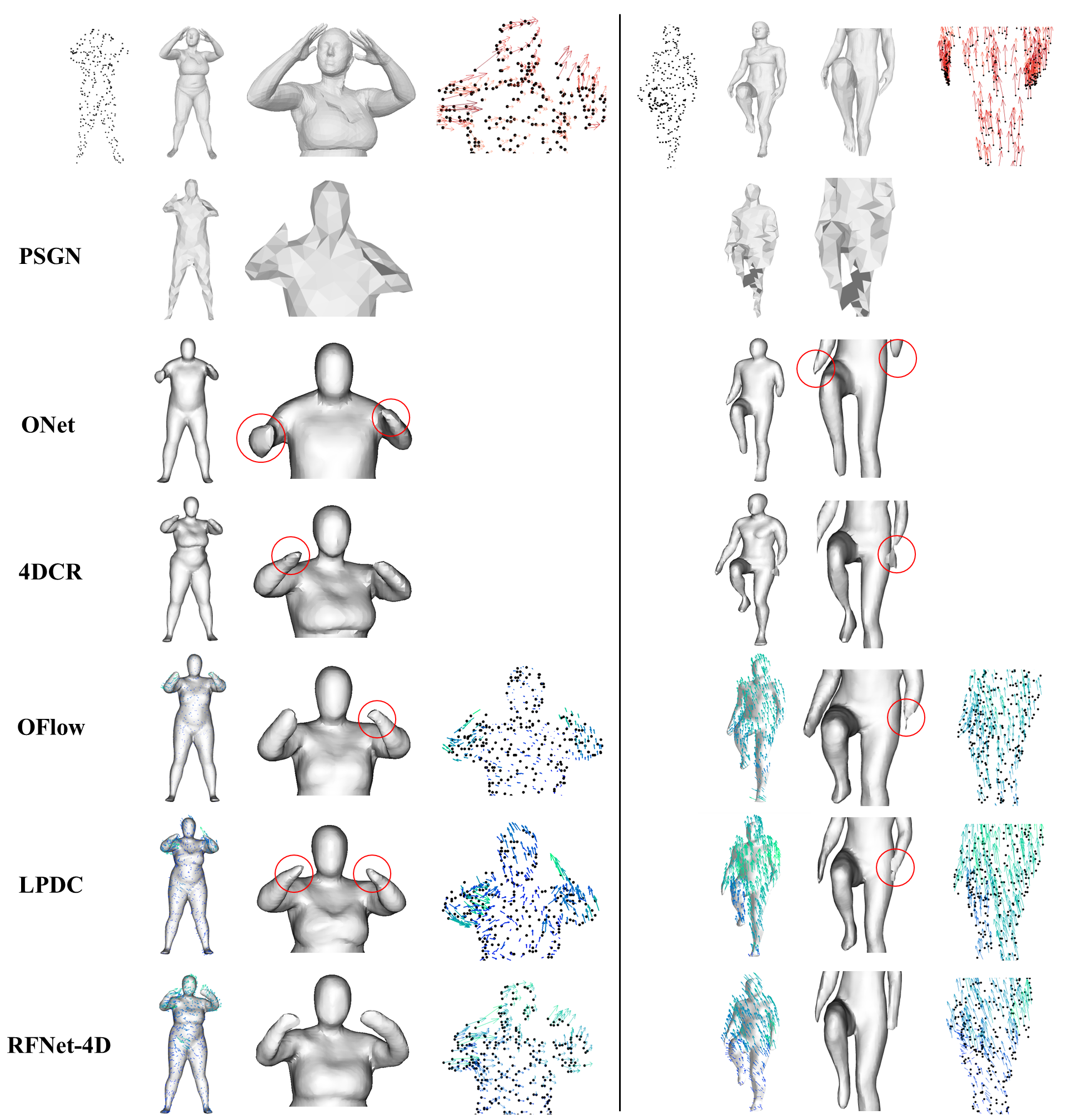
Qualitative Results
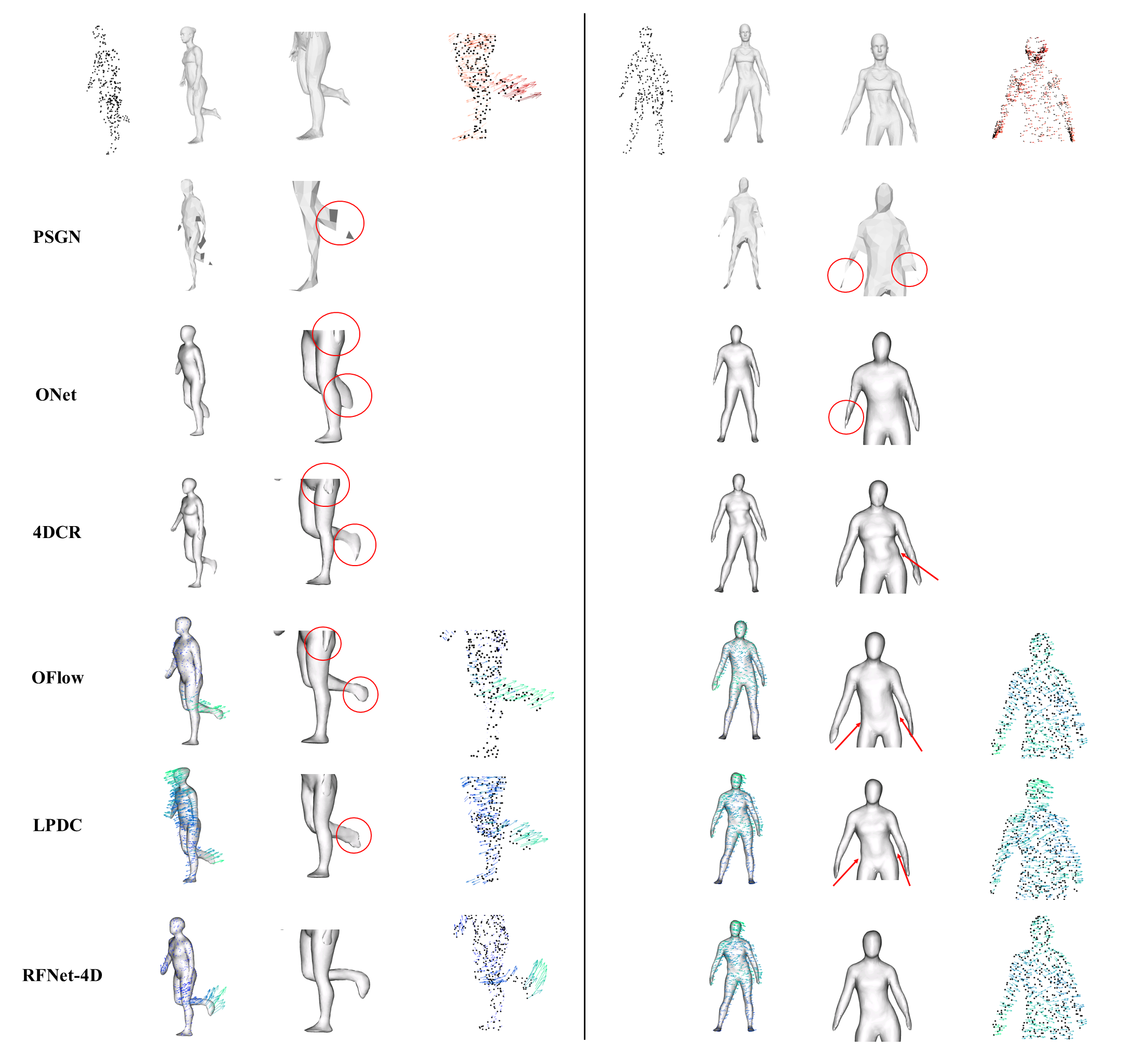
The first row includes (from left to right): input point cloud, ground truth mesh of entire body, ground
truth mesh of upper/lower body, and ground-truth flows (darker vectors show stronger motions). Each
following row represents corresponding reconstruction and flow estimation results. Severe errors are
highlighted.
Citation
@inproceedings{tavu2022rfnet4d,
title={RFNet-4D: Joint Object Reconstruction and Flow Estimation from 4D Point Clouds},
author={Tuan-Anh Vu, Duc-Thanh Nguyen, Binh-Son Hua, Quang-Hieu Pham, Sai-Kit Yeung},
booktitle={Proceedings of European Conference on Computer Vision (ECCV)},
year={2022}
}
Acknowledgements
This paper was partially supported by an internal grant from HKUST (R9429). The website is modified from this template.